Paper Reading on Deep Compressed Sensing
1. Learning a Compressed Sensing Measurement Matrix via Gradient Unrolling
1.1 Abstract
Linear encoding of sparse vectors is widely popular, but is commonly data-independent – missing any possible extra (but a priori unknown) structure beyond sparsity. In this paper, we present a new method to learn linear encoders that adapt to data, while still performing well with the widely used
decoder. The convex decoder prevents gradient propagation as needed in standard gradient-based training. Our method is based on the insight that unrolling the convex decoder into T projected subgradient steps can address this issue. Our method can be seen as a data-driven way to learn a compressed sensing measurement matrix. We compare the empirical performance of 10 algorithms over 6 sparse datasets (3 synthetic and 3 real). Our experiments show that there is indeed additional structure beyond sparsity in the real datasets; our method is able to discover it and exploit it to create excellent reconstructions with fewer measurements (by a factor of 1.1-3x) compared to the previous state-of-the-art methods. We illustrate an application of our method in learning label embeddings for extreme multi-label classification, and empirically show that our method is able to match or outperform the precision scores of SLEEC, which is one of the state-of-the-art embedding-based approaches.
1.2 Introduction
Design a measurement matrix
The problem can be solved as follows:
But it's a NP-Hard problem. With some properties such as Restricted Isometry Property (RIP) or the nullspace condition (NSP),
The authors interested in vectors that are not only sparse but have additional structure in their support. They propose a data-driven algorithm that learns a good linear measurement matrix
Our method is an autoencoder for sparse data, with a linear encoder (the measurement matrix) and a complex non-linear decoder that approximately solves an optimization problem.
PCA is a data-driven dimensionality reduction method and an autoencoder with encoder and decoder all linear, and is provides the lowest MSE. Linear encoder has advantages, 1) easy to compute matrix-vector multiplication; 2) easy to interpret as every column of the encoding matrix can be viewed as feature embedding. Arora et al. found that pre-trained word embeddings such as GloVe and word2vec formed a good measurement matrices for text data, which need fewer mearusements than random matrces when used with
Given
where
这个步骤就被称为梯度展开(gradient unrolling)。推导过程:
- 原始最小化问题:
- 映射子梯度方法的更新为
其中,
这里的
使用
根据一个引理,我们有理由使用
引理要求
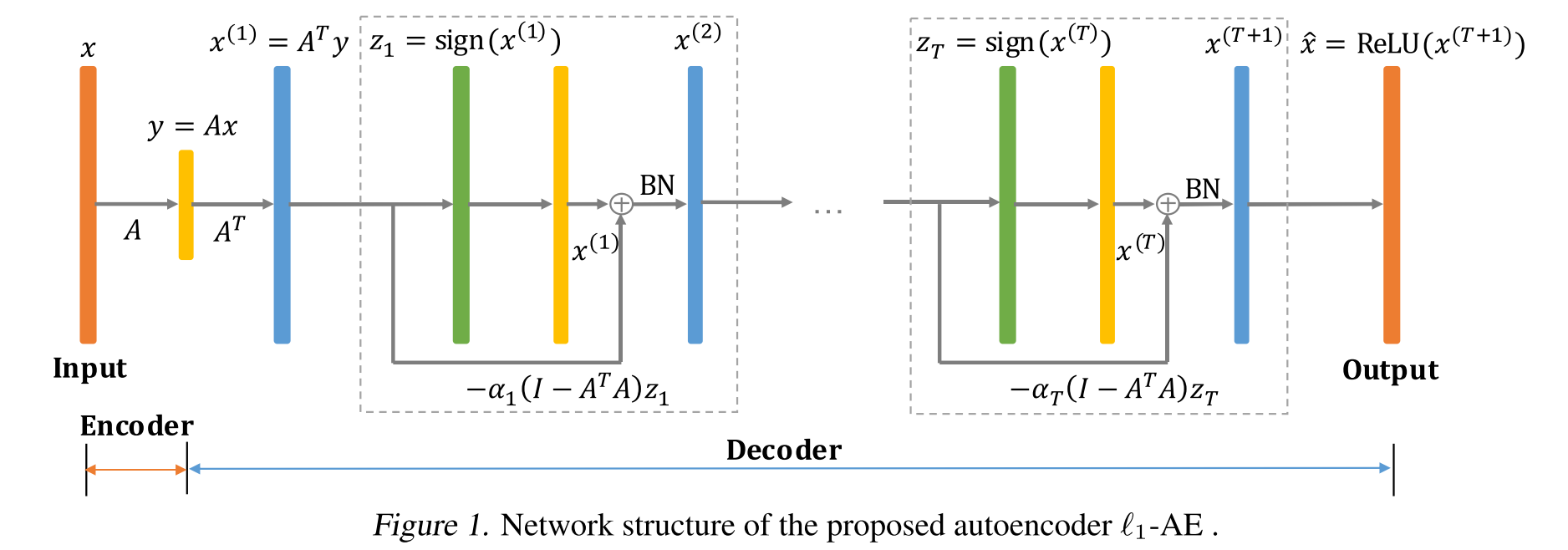
经过block,输出为
对于这样学到的线性编码器Gurobi进行解码,因此整套算法可以写成L1-AE+L1-min pos。这样学到的编码器与
作者还发现
2. Deep Compressed Sensing
2.1 Abstract
Compressed sensing (CS) provides an elegant framework for recovering sparse signals from compressed measurements. For example, CS can exploit the structure of natural images and recover an image from only a few random measurements. CS is flexible and data efficient, but its application has been restricted by the strong assumption of sparsity and costly reconstruction process. A recent approach that combines CS with neural network generators has removed the constraint of sparsity, but reconstruction remains slow. Here we propose a novel framework that significantly improves both the performance and speed of signal recovery by jointly training a generator and the optimisation process for reconstruction via metalearning. We explore training the measurements with different objectives, and derive a family of models based on minimising measurement errors. We show that Generative Adversarial Nets (GANs) can be viewed as a special case in this family of models. Borrowing insights from the CS perspective, we develop a novel way of improving GANs using gradient information from the discriminator.
压缩传感(CS)提供了一个优雅的框架,可从压缩测量中恢复稀疏信号。例如,CS可以利用自然图像的结构并仅从几个随机测量中恢复图像。CS具有灵活性和数据效率,但是其应用受到稀疏性的强烈假设与昂贵的重建过程的限制。将CS与神经网络生成器结合在一起的最新方法消除了稀疏性的约束,但是重建仍然很慢。在这里,我们提出了一个新颖的框架,该框架通过联合训练生成器和通过元学习进行重构的优化过程,可以显着提高信号恢复的性能和速度。我们探索了训练具有不同目标的测量,并基于最小化测量误差得出一系列模型。我们表明,在该系列模型中,可以将生成对抗网络(GAN)视为特例。从CS角度汲取见解,我们开发了一种使用鉴别器中梯度信息来改进GAN的新颖方法。
2.2 Introduction
编解码是通信的核心问题,压缩感知(CS)提供了一个将编码和解码分离成独立的测量和重建过程的框架。
- 自动编码器:端到端训练
- CS:在线优化,从低维测量中恢复高维信号,很少或不需训练
但是CS在处理大规模数据时却因为稀疏假设与重建效率而被阻碍。Bora et al., 2017将CS与独立训练的神经网络生成器合并。本文则提出深度压缩感知(Deep Compressed Sensing,DCS)框架,神经网络同时对测量和重建从头训练。这个框架自然导出了一系列模型,包括GAN,是通过训练不同目标的测量函数得到。文章的贡献有:
- 展示了如何在CS框架内训练深度神经网络
- 元学习的重建过程导致更精确、数量级上更快的方法
- 开发了基于潜在优化的GAN训练算法,提升了GAN的性能,使用不饱和生成器损失
作为测量误差 - 我们将框架扩展到半监督的GAN,并表明潜在优化在语义上有意义的潜在空间中产生
2.3 Background
2.3.1 Compressed Sensing
参考自Donoho, 2006; Candes et al., 2006。
式中
这里
这个约束优化问题很难计算,但采样过程相对简单。
2.3.2 Compressed Sensing using Generative Models
稀疏性的要求限制了CS的应用,傅立叶基和小波基也只是部分缓解了这种限制,因为它们只能用于已知在这些基中稀疏的域。Bora et al., 2017提出使用生成模型的压缩感知(Compressed Sensing using Generative Models, CSGM)放宽这种要求。这个模型使用VAE或GAN预训练的深度神经网络
重建信号为
通常,需要数百或数千个梯度下降步骤以及从初始步骤重新启动几个步骤才能获得足够好的Bora et al., 2017; Bojanowski et al., 2018。这项工作建立了压缩感知与深度神经网络的联系,且优于LassoTibshirani, 1996。Hand & Voroninski, 2017; , Dhar et al., 2018有在理论与实践上的进展。但仍有两方面的限制:
- 重建的优化需要上千步梯度下降,依然很慢
- 依赖于随机测量矩阵,对自然图像这样的高度结构化数据并不是最优的,经过学习的测量可能表现更好
2.3.3 Model-Agnostic Meta-Learning
元学习允许模型通过自我完善来适应新任务,与模型无关的元学习(MAML)提供了一种通用的方法来为许多任务调整参数Finn et al., 2017。
文章提出的MAML可以用于任何使用梯度下降进行训练的问题和模型,除了深度神经网络,分类、回归、策略梯度强化学习等不同的结构和任务都可以在很小的改动下解决。在元学习中,训练模型的目标是从新的小规模样本中快速学习新任务,此外,模型由元学习器训练以有能力学习大量的不同任务。关键思路是训练模型的初始化参数,以使模型在新任务上通过计算少量新的数据进行一次或多次梯度步骤更新参数而拥有最好的性能。不像之前的思路,更新函数或学习规则,这个算法没有增加学习参数的数量,也不对模型做限制。
对每个任务:
元学习:
2.3.4 Generative Adversarial Networks
生成对抗网络(GAN)训练参数化生成器Goodfellow et al., 2014。
2.3 深度压缩感知
首先,把 MAML 与 CSGM 相结合;之后将测量矩阵参数化,如使用 DNN。之前的工作使用随机映射作为测量,本文则将 RIP 作为训练目标,学习测量函数。之后通过在测量中施加 RIP 以外的其他性质,产生了两个新模型,包括带有判别器引导的潜在优化的 GAN 模型,导致更稳定的训练动态和更好的结果。
2.3.1 元学习压缩感知
CSGM 使用梯度下降,在隐空间内优化损失函数:
然而,这种优化可能需要上千个优化步骤,效率比较低。本文提出使用元学习的方法来优化这个重建过程。
3. Compressed Sensing using Generative Models
3.1 Abstract
The goal of compressed sensing is to estimate a vector from an underdetermined system of noisy linear measurements, by making use of prior knowledge on the structure of vectors in the relevant domain. For almost all results in this literature, the structure is represented by sparsity in a well-chosen basis. We show how to achieve guarantees similar to standard compressed sensing but without employing sparsity at all. Instead, we suppose that vectors lie near the range of a generative model
. Our main theorem is that, if G is L-Lipschitz, then roughly random Gaussian measurements suffice for an recovery guarantee. We demonstrate our results using generative models from published variational autoencoder and generative adversarial networks. Our method can use 5-10x fewer measurements than Lasso for the same accuracy.
压缩感知的目标是通过利用相关域内向量结构的先验知识,从欠定的噪声线性测量系统中估计向量。在几乎所有相关文献的结果里,结构由在精心选择的基中的稀疏性所表示。我们展示了如何在完全不使用稀疏性的情况下实现与标准压缩感知相似的保证。与之相反,我们假设向量位于生成模型
3.2 Introduction
其中,
这篇文章依赖于生成模型产生的结构,而不是稀疏性。VAE、GAN等基于神经网络的生成模型在对数据分布建模上取得很多成果。这些模型的生成部件学习一个从低维表示空间
主要创新:提出了一个使用生成模型进行压缩感知的算法。使用梯度下降优化表示
我们的理论结果表明,只要梯度下降可以找到我们目标的良好近似解,输出
有定理:如果测量矩阵在给定生成器G的范围内满足S-REC,那么最小化测量误差的最佳值接近真实的
<!-- TODO -->
4. Task-Aware Compressed Sensing with Generative Adversarial Nets
4.1 Abstract
In recent years, neural network approaches have been widely adopted for machine learning tasks, with applications in computer vision. More recently, unsupervised generative models based on neural networks have been successfully applied to model data distributions via low-dimensional latent spaces. In this paper, we use Generative Adversarial Networks (GANs) to impose structure in compressed sensing problems, replacing the usual sparsity constraint. We propose to train the GANs in a task-aware fashion, specifically for reconstruction tasks. We also show that it is possible to train our model without using any (or much) non-compressed data. Finally, we show that the latent space of the GAN carries discriminative information and can further be regularized to generate input features for general inference tasks. We demonstrate the effectiveness of our method on a variety of reconstruction and classification problems.
近年来,神经网络方法已广泛用于机器学习任务,并应用于计算机视觉。最近,基于神经网络的无监督生成模型已成功应用于通过低维潜在空间进行数据分布建模。在本文中,我们使用生成对抗网络(GAN)在压缩感知问题中施加结构,从而取代了通常的稀疏约束。我们提出以任务感知方式训练GAN,尤其是针对重建任务。我们还表明,无需使用任何(或大量)非压缩数据即可训练模型。最后,我们证明了GAN的潜在空间带有判别信息,并且可以进一步进行正则化以生成用于一般推理任务的输入特征。我们证明了我们的方法在各种重构和分类问题上的有效性。
4.2 Introduction
这篇文章是在 [Bora et al.][1] 的基础上进行的工作。[Bora et al.] 使用生成模型替代了压缩感知问题中的稀疏性假设,并且证明在生成模型满足一定条件,且测量矩阵为独立同分布的随机高斯分布时,在很高的概率下有
[Bora et al.] 的文章中,损失函数取为
[Kabkab et al.] 首先证明了,在一定的假设下,有
这表明 (1) 式右侧非常小。但以上定理的假设太严格,很难达到,因此 [Kabkab et al.] 考虑进行任务感知的 GAN 训练,允许生成器 G 对压缩感知重建任务进行优化。[Kabkab et al.] 对 Goodfellow 提出的的 GAN 的训练过程进行了修改,增加了对 (2) 式损失函数进行 GD 优化的步骤,再利用得到的隐变量
更进一步地,考虑到在压缩感知的任务中对采样过程进行压缩,非压缩的数据往往难以获得,因此提出基于一小部分的非压缩数据及大部分的压缩数据作为训练集进行训练。此算法训练两个判别器和一个生成器,第一个判别器分辨实际的训练数据
因为隐变量
作者在 MNIST、F-MNIST、CelebA 三个数据集上进行了实验。
5. Compressed Sensing with Invertible Generative Models and Dependent Noise
5.1 Abstract
We study image inverse problems with invertible generative priors, specifically normalizing flow models. Our formulation views the solution as the Maximum a Posteriori (MAP) estimate of the image given the measurements. Our general formulation allows for non-linear differentiable forward operators and noise distributions with long-range dependencies. We establish theoretical recovery guarantees for denoising and compressed sensing under our framework. We also empirically validate our method on various inverse problems including compressed sensing with quantized measurements and denoising with dependent noise patterns.
我们研究具有可逆生成先验的图像逆问题,特别是归一化流量模型。我们的公式将解决方案视为给定测量值的图像的最大后验(MAP)估计值。 我们的一般公式允许非线性可微正向算子和具有长期依赖性的噪声分布。我们在我们的框架下为消噪和压缩感知建立了理论上的恢复保证。我们还根据经验验证了我们的方法在各种反问题上的应用,包括采用量化测量值进行压缩感测以及采用相关噪声模式进行降噪的方法。
5.2 Introduction
- 逆问题:从观测中重建未知的信号,图像等
- 对通过不可逆的正向过程获得观测结果的情况感兴趣,这里有信息损失
- 成像算法依赖先验知识对成像数据建模
, 是观察到的测量, 是确定且已知的正向算子, 是可能有着复杂结构的加性噪声 建模了物理过程,如MRI、压缩感知、相位检索
- 线性逆问题:
,测量矩阵为 ; - 降噪,压缩感知,超分辨,图像补全
- 稀疏或者说结构稀疏是很有影响力的用于逆问题的结构先验
- 最近,深度生成模型作为图像先验被引入,性能优于稀疏先验
- 可逆深度生成模型
- 或者说,归一化流,是一类新的深度生成模型,可以通过构造进行高效采样、反演、似然估计,deepmind Normalizing Flows for Probabilistic Modeling and Inference
- Asim 的 Invertible generative models for inverse problems 与 Bora 的 csgm 相比,带来了显著的性能提升,尤其对于分布外的样本进行成像时。受此启发,我们扩展了 Asim 的思路到噪声分布与可微分的正向算子上
- 贡献如下:
- 我们提出了一种通用公式,以获得相关噪声和一般正向算子的最大先验(MAP)估计重构;线性逆问题与高斯噪声使用 Asim 的思路
- 将可逆生成模型应用到重建图像与结构噪声中;如处理可变方差的噪声或具有MNIST数字结构的从属噪声
- 展现了重建方法的两种理论结果。降噪问题:如果生成模型的 log 似然函数在真实图像周围局部强凹,那么可以证明梯度下降实现了取决于局部凸度参数的误差的减小;压缩感知:随机测量矩阵,MAP公式下可以限制恢复误差
- 实验显示了在具有各种复杂和相关结构噪声存在时完美的重建;使用此方法在 CelebA-HQ 和 MNIST 上进行了多种逆问题,包括降噪与量化的压缩感知
5.3 预备知识
5.3.1 可逆生成模型
- 可逆生成模型,AKA 归一化流模型,通过可微可逆的函数
映射简单噪声来近似复杂分布,通常为独立高斯噪声 - 采样:简单分布生成
,计算 。 - 因为
是可逆的,由密度函数变换可知: ,即 ,其中 是 在 处的雅各布矩阵。 是简单分布,只要能快速计算 和对数行列式,在任意点 处计算似然性就会很直接 - 满足可计算的可逆与对数行列式的神经网络生成器:NICE、RealNVP、IAF、iResNet、Glow、FFJORD
- 因为
- Normalizing Flows:
- 归一化流通过应用一系列可逆转换函数将简单分布转换为复杂分布;根据变量变化的理论获得最终的分布
,所以 - 全链叫做归一化流;因此需满足1易计算反函数2雅各比行列式易计算这两个条件
- 归一化流模型
- 训练目标:负对数似然:
- RealNVP:
- Real-valued Non-Volume Preserving,堆叠一系列可逆双射变换函数。
- 所谓双射函数,即仿射耦合层
- 输入维度分解为两部分:1. 前d维保持 2. d+1到 D维,仿射变换(放缩平移),且放缩与平移的参数为前d维的函数
;
- 这种变换满足前述条件
; -
- 同时,不需要计算s和t的逆与雅各比,s和t可以很复杂,如使用神经网络
- 每层保持不同的地方不变;BN有助于训练
- 多尺度架构
- NICE,Non-Linear Independent Component Estimation,非线性独立分量估计
- RealNVP,取消放缩,只有平移
- Glow:扩展RealNVP,1x1卷积替换反向排列。三个步骤:
- Activation normalization 激活归一化:类似于BN的仿射变换,batchsize为1,参数可学习
- 可逆1x1卷积:RealNVP各层间通道反向排列;输入输出数相同的1x1卷积是对通道排列的泛化。
, 维度 , 维度 。 - 逆 1x1卷积依赖于
,运算量很小
- 仿射耦合层ACL:RealNVP
- 训练目标:负对数似然:
5.3.2 相关工作
- 深度生成先验用于压缩感知与其他逆问题始于Bora的CSGM,该文中GAN与VAE对压缩感知而言是一种有效的先验;
- 其他工作调研了两者结合的其他方法:
- Dhar 在生成器的范围内添加了稀疏偏差
- Van Veen 将未训练的CNN作为成像任务的先验,基于深度图像先验
- Wu 的 DCS 使用元学习提升重建速度
- Ardizzone 通过使用流模型对正向过程进行建模,可以通过模型的可逆性隐式学习逆过程
- Asim 提出使用归一化流模型替换CSGM的GAN先验,报告了出色的泛化性能,尤其是在重构失配图像时
5.4 方法
MAP 公式
- 观测:
, , , 为确定可微正向算子 - 给定观测
,最小化如下 loss 来恢复 : - 这个loss的最小值是后验概率
的最大后验(MAP)估计
- 定义可逆映射
,使用流模型 对 建模。 - 如果
比较完美,那么 - 又
,故
- 如果
- 上述优化目标非凸,但可微,可以使用基于梯度的优化器;实践中,非完美模型与大致优化即可在很多任务上表现良好
与之前工作的联系
- 此文基于 Bora 的 CSGM 与 Asim 的 IGMIP
- CSGM:GAN Prior
- 通过隐变量的二范数正则化,将
投影到生成器的值域上;与MAP loss不同 - 生成器不可逆,将噪声映射到高维向量;真实图像可能不在生成器的值域内;Asim也指出了无法表示任意输入的问题,这确实导致重建效果不佳
- 此公式无概率上的解释,因为 GAN 不提供似然
- Flow Prior
- 同时匹配观测、最大化似然:
- 当噪声为各向同性高斯分布时,即
,MAP loss 即为这种形式。因为 ,因此 -
- 因为存在优化上的困难,Asim 提出代理loss
- 假设噪声各向同性高斯,且流量先验保持保持体积不变,即对数行列式为常量,那么
- 那么
- 体积不变性的结构有 NICE 与带加性耦合层的Glow
- 假设噪声各向同性高斯,且流量先验保持保持体积不变,即对数行列式为常量,那么
- 同时匹配观测、最大化似然:
5.5 理论分析
不考虑信号的特定结构如稀疏与低维高斯生成先验。考虑普通设定,研究预训练流模型如何降低去噪问题的误差或减少压缩感知问题的测量数。
去噪问题的理论保证
, - loss 为
, - 定理:假设
为模型 的局部最优点,假设 的邻域球 上 满足强凸性,即 ,可以证明梯度下降收敛值 满足 - 也就是说,局部强凸性提升了去噪的质量,
更大的定义良好的模型去噪更好;最大似然训练目标与更好的降噪性能保持一致。
压缩感知的理论保证
- 定理:给定
, , 是概率密度高于真实图像的集合, ,服从 , 。求解如下带约束优化问题: -
- 可得:
-
- 其中
为集合 的高斯平均宽度。高斯平均宽度与集合的大小同阶,而 越大, 就越小,因此上述上界对高概率密度的 更紧。 是全局最大值时,复原误差为0。 - 定义高斯平均宽度:
,直觉上就是集合的复杂度。
- 定义高斯平均宽度:
5.6 实验
(1)非线性正向算子,(2)具有相关性的复杂噪声,以及(3)高维可伸缩性。
数据集与结构
- 多尺度 RealNVP 模型;MNIST 与 CelebA-HQ。
- 公开的预训练 Glow 模型
- 测试:100 for CelebA and 1000 for MNIST
基线方法
- Bora,Asim
- BM3D for denoising
- 1-bit compressed sensing,no LASSO as quantization and non-Gaussian noise
模型平滑参数
中,未知的真实数据分布 由流模型 给出密度近似。因此对 的复原依赖于密度估计的质量 - 基于似然的模型存在反直觉的性质:对分布外样本指定高密度
- 为纠正这一点,使用
进行平滑 -
,only noise; ,only model; 控制对 的依赖程度
结果
- 移除 MNIST 噪声:
, - 使用MNIST训练的流模型生成作为噪声,添加到不同的通道与位置上;
- 图像分解任务
- Bora 移除了,因为所有生成由DCGAN得到
- 移除正弦噪声:
, - 每行服从高斯分布,方差为正弦;
- 移除径向噪声:
, - 每个像素服从高斯分布,方差由中心向四周指数衰减
- 带噪声的1比特压缩感知
- 非线性正向算子与非高斯噪声
, 为随机高斯测量矩阵,噪声为1维正弦噪声,具有恒定的偏移量,平均值为正 - 最极端的量化压缩感知,观测结果为
;正均值噪声使信号由负翻转为正,对零均值假设进行了挑战 - 梯度为0,使用 straight-through estimator 进行反向传播
- 亚像素插补
, 为随机二值mask;随机丢掉 25%的亚像素,尝试补全 - 线性无噪声,256*256 图片,预训练Glow模型
- 结果证实方法与框架无关,恢复质量与运行时间可扩展到高维
5.7 结论
- 提出新方法,逆问题,通用可微正向算子,结构噪声
- 与基线的比较不公平,因为此方法了解噪声结构,其他方法没有这种设计
- 可视为 Asim 的补充到更通用的正向算子与噪声模型
- 我们的方法之所以强大,是因为可逆生成模型的灵活性,可以将其以模块化的方式组合起来,以解决非常普遍的情况下的MAP逆问题。
- 仍然存在的中心理论问题是分析我们制定的优化问题。
- 在本文中,我们使用梯度下降从经验上最小化了这种损失,但一些理论上的保证可能会非常有趣,可能是在假设条件下,例如: 随机权重遵循Hand和Voroninski的框架
6. Back-Projection based Fidelity Term for Ill-Posed Inverse Problems
不适定线性逆问题的基于反投影的保真项
6.1 Introduction
Ill-posed linear inverse problems appear in many image processing applications, such as deblurring, super- resolution and compressed sensing. Many restoration strategies involve minimizing a cost function, which is composed of fidelity and prior terms, balanced by a regularization parameter. While a vast amount of research has been focused on different prior models, the fidelity term is almost always chosen to be the least squares (LS) objective, that encourages fitting the linearly transformed optimization variable to the observations. In this paper, we examine a different fidelity term, which has been implicitly used by the recently proposed iterative denoising and backward projections (IDBP) framework. This term encourages agreement between the projection of the optimization variable onto the row space of the linear operator and the pseudo- inverse of the linear operator (“back-projection”) applied on the observations. We analytically examine the difference between the two fidelity terms for Tikhonov regularization and identify cases (such as a badly conditioned linear operator) where the new term has an advantage over the standard LS one. Moreover, we demonstrate empirically that the behavior of the two induced cost functions for sophisticated convex and non-convex priors, such as total-variation, BM3D, and deep generative models, correlates with the obtained theoretical analysis
不适定的线性逆问题出现在许多图像处理应用中,例如去模糊,超分辨率和压缩感知。许多恢复策略涉及使成本函数最小化,该成本函数由保真度和先验项组成,并由正则化参数进行平衡。大量研究集中在不同的先前模型上,但保真度术语几乎总是被选为最小二乘(LS)的目标,这鼓励将线性变换的优化变量拟合到观测值。在本文中,我们检查了一个不同的保真度项,该项已被最近提出的迭代去噪和反向投影(IDBP)框架隐式使用。该项鼓励优化变量在线性算子的行空间上的投影与应用于观测值的线性算子的伪逆(“反投影”)之间的一致。我们分析了两个保真项之间的差异,以进行Tikhonov正则化,并确定了新项比标准LS项具有优势的情况(例如条件不佳的线性算子)。此外,我们通过经验证明,复杂的凸和非凸先验的两个诱导成本函数的行为,例如总变异,BM3D和深度生成模型,与所得理论分析相关。